ID er 'en levende vitenskap'
(Fra 'Signature in the cell' Epilog; S.C.Meyer; Harper One)
Mens noen argumenterer mot at Intelligent Design (ID) kan kalles vitenskap, argumenterer andre mot aktualiteten til ID. De kan nok hevde at den er vitenskap, men 'det gir ikke lenger et nyttig fortolkende rammeverk, fordi den mangler forklarende kraft'. Dette hevdes bl.a. av vitenskapsfilosof Philip Kitcher, University og Colombia. Men stemmer det at ID feiler i å forklare nåværende DNA-bevis fra studier om arvemateriale?
I dette avsnittet vises at ID er 'en levende vitenskap' som kan forklare nye funn om arvematerialet. Det er først de senere år at flere av oppdagelsene under er kommet fram i lyset.
Forklarende kraft ved ID
For å lykkes som vitenskap, er det viktig med et fortolkende rammeverk for å forklare nye bevis, inklusive det alternative teorier har problemer med å forklare. Det har skjedd gjentatte ganger i vitenskapshistorien at nye teorier har blitt akseptert hovedsakelig på grunn av deres evne til å forklare etablerte fakta bedre enn konkurrentene. Om en teori kan gi et nyttig rammeverk for å forstå og fortolke en bred rekke bevis, spesielt bevis som nylig er avdekket, så kan den virke tiltrekkende på mennesker som søker forklaring. Det fins resultater vi ville forvente om ID hadde vært årsak til dem, og andre typer resultater -om bare mutasjoner og naturlig utvalg hadde dannet dem.
Vi vet av erfaring fra vår verden hvordan intelligente aktører designer informasjons-prosesserings og lagrings-systemer. De organiserer informasjonen for å maksimere lagrings-tettheten og rask innhenting, gjerne via hierarkiske strukturer. En ønsker gjerne maksimere en eller to målsettinger, og det gjøres gjerne ved 'byttehandel' mellom dem. I cellen er det to slike kjennemerker: funksjonell, spesifikk informasjon og et informasjonssystem for å prosessere denne informasjonen.
Selv om evolusjonsbiologer påpeker at mutasjoner og naturlig utvalg kan skape inntrykk av design, så er det slett ikke alle design-egenskaper som forklares ved hjelp av dette. Siden naturlig utvalg pr. definisjon er ikke-styrt, kan den ikke forklare design som det krever 'forsyn/planlegging' å bringe sammen. Siden naturlig utvalg bare virker på det som mutasjoner først har dannet, så forklarer det ikke uttrykk for design som krever diskrete hopp, eller kompleksitet som overstiger rekkevidden til tilfeldighet (det mulige utfallsrommet).
Så hva ville vi vente å finne i arvematerialet om ID var forklaring på livets opphav, og hva ville vi vente finne om ikke-styrte prosesser som mutasjoner og utvalg var det?
 Ny kunnskap om arvematerialet
Ny kunnskap om arvematerialet
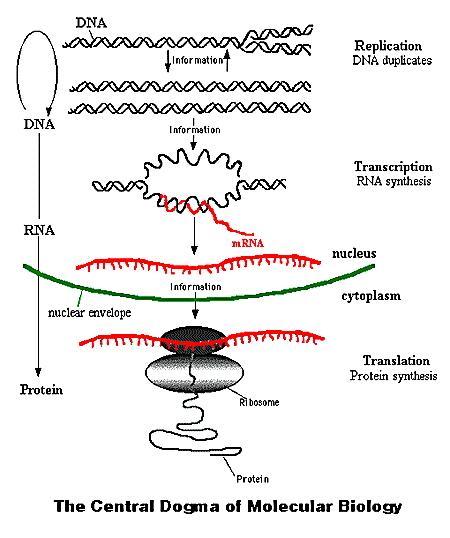
I løpet av de siste 15-20 årene har genetiske studier revolusjonert vår forståelse av hvordan cellen samvirker med genetisk og annen biologisk informasjon. Biologer bekrefter fortsatt at DNA inneholder spesifikk informasjon, men har oppdaget at systemet med lagring og behandling av denne informasjonen er enda mer kompleks enn antatt inntil nylig. Tidligere antok en at informasjonen for å bygge et protein vanligvis befinner seg ett sted langs DNA-molekylet. En har også funnet ut at et gen ikke alltid koder for bare ett protein, slik en har trodd i 70 år.
RNA som en trodde kun ble brukt til 'oversetting' av koder, styrer også prosessering av annen genetisk informasjon. Videre er det tilleggs prosesser som editerer kjedene med aminosyrer før de foldes i tredimensjonale strukturer. Like revolusjonerende er det at biologisk informasjon utenfor DNA utgjør en kritisk rolle i utviklingen av organismer.
I det hele har det utviklet seg en ny forståelse av genet. En forstår ikke genet lenger som en enkel, lineær og lokal enhet. I stedet oppfattes det som et et distribuert sett med data-filer, tilgjengelig for gjenfinning og kontekst-avhengig uttrykk, ved et komplekst informasjons-prosesserings system. Det tilsvarer mer hvordan data lagres på en harddisk med pekere, og der det er fysisk mulig og med mest mulig nærhet. Cellens informasjonssystem inneholder således kjennetegn vi hittil bare har funnet i intelligent konstruerte systemer. Basert på vår nåværende kjennskap til årsak og virknings-lovene i verden, kjenner vi bare én mulig årsak til slike systemer -intelligens. At ID slik kan fortolke ny informasjon, understreker dets evne til å gi et fortolkende rammeverk for biologisk forskning.
Det er tre oppdagelser angående cellens informasjonssystem som illustrerer ID's evne til å forklare ellers vanskelig forståelige oppdagelser: 1. Funksjonell, spesifikk informasjon er tett konsentrert i DNAet. 2) Genomet (en celles totale mengde av genetisk materiale, dvs. samtlige gener på alle kromosomer) er hierarkisk organisert, for å lette tilgang og gjenfinning av informasjon. 3) Organismen gir en informasjonsrik kontekst- som involverer informasjon både i og utenfor genomet. Det er dette (både innholdet og plasseringen) som bestemmer uttrykksmåten til lavere-nivå genetisk informasjon.
 1. Konsentrasjonen av informasjon i DNA
1. Konsentrasjonen av informasjon i DNA
Mens evolusjonister før proklamerte at mesteparten av DNAet var søppel (junk-DNA), har en måttet endre oppfatning av dette. Genetisk informasjon i DNA er organisert for å maksimere informasjonstettheten. Selv om noe innhold er degradert over tid, så er den store majoriteten av base-sekvenser i genomet essensielle for å utøve biologiske funksjoner. Dette gjelder også de mange sekvensene som ikke er koder for protein. Genetiske signaler er altoverveiende i forhold til 'støy', slik ID-tilhengere forutsa tidlig på 1990-tallet.
Genom studier viser også at cellen adresserer distribuerte genetiske data-sett og så henter spesifikk informasjon for å styre produksjonen av protein, mye lik operativisystemet i en computer. Mer enn enkle strenger, blir det snakk om spesifiserte base-selvenser plassert rundt om på DNA-spiralen, noen ganger også rundt på ulike kromosomer. I tillegg til genetisk kode, bruker cellens informasjonssystem andre høy-nivå koder som bestemmer hvordan ulike moduler av genetisk informasjon skal hentes og behandles før oversettelse finner sted.
Det er også en enda mer slående måte som genomet maksimerer informasjonslagring på: multiple beskjeder kan ligge lagret i den samme base-sekvensen eller regionen i genomet. Faktisk kan ett gen i samarbeid med koder utenom genomet, produsere mange tusen ulike RNA-beskjeder og proteiner. Som et resultat av overlappende genetiske beskjeder og ulike slag informasjons prosessering, anses nå informasjonsmengden i DNAet å være ekstremt mye større enn tidligere kjent.
DNA-sekvenser (introns) som tidligere ble ansett for å være 'meningsløse' er nå funnet å romme gener som kan bygge proteiner. I tillegg har individuelle introns implantert i seg koder for regulerende og strukturelle RNA-er. Slik sett opptrer de som russiske dukker, som inneholder multiple beskjeder inn i seg selv, og selv er del av en større genetisk beskjed. (Fra dataspråket kjenner vi Object-Linked-Embedding (OLE), som gjør at et objekt skapt av én applikasjon kan innlemmes i et dokument skapt av en annen applikasjon, uten å miste noen kjennetegn..)
Fra den amerikanske borgerkrigen kjenner vi til et brev, som tilsynelatende berettet om dagligdagse hendelser på en gård. I virkeligheten inneholdt brevet kode for størrelse på troppeforflytninger, og et nært forestående angrep. På samme måten har celle protein-'maskineri' som samtidig fungerer som en tallkode for å lese og aksessere de iboende beskjedene fra de primære beskjedene i genomet.
Det at genomet er organisert for å samhandle med informasjon lagret annetsteds, understreker ytterligere hvordan genomet er organisert for å øke dets kapasitet til å lagre informasjon. Denne enorme informasjonstettheten bare øker forklaringstyngden til ID. Informasjonsmengden var også tidligere kjent å overstige mulighetene som universet hadde til å danne den type spesifikk og kompleks informasjon. Nå er det enda mye mer. Eksistensen til dual-koding og overlappende protein-informasjon er virtuelt umulig ved tilfeldigheter (W.Y. Chung, Center for Comparative genomics og Bioinformatics, Pett State University). Dette er bare en av mange cellulære innovasjoner for å konsentrere genomisk informasjon. Selv om dette er ekstremt, er det ikke unaturlig, ut fra ID-sammenheng. Tidligere forutsigelser fra evolusjonært hold om masse 'junk' DNA, ville påføre cellen mye ekstra ressurs-omkostninger. Men basert på erfaring med hvordan intelligente aktører krypterer og effektiviserer gjenfinning, er ikke cellens effektive informasjons-system uventet fra ID-hold.
Cellen har også indeks-koder som gjør cellen i stand til å lokalisere og forholde seg til spesifikke moduler med genetisk informasjon. Dette gjør at den kan fungere også under vekslende forhold i omgivelsene (som 'stress' og endring i nærområdet). Selv om biologi og computer systemer bruker ulikt materiale, finner en mange likheter med hvordan operativsystemet i PC-er gjenfinner informasjon og samler den i filer. Metainformasjon med koder skjult i opprinnelig betydning, er noe vi vanligvis bare forbinder med intelligent aktivitet.
 2. Hierarkiske arrangement , optimalisert for tilgang og gjenfinning
2. Hierarkiske arrangement , optimalisert for tilgang og gjenfinning
På samme måte som ord ordnes i setninger, setninger i avsnitt, avsnitt i kapitler, kapitler i bøker, så viser studier av genomet at vi har mye av samme hierarkiske organsiering der. Genene er sekvensielt ordnet for å aktivere produksjon og effektiv regulering av bestemte RNAs og proteiner. Gruppering av gener kan sammenlignes med gruppering av filer i mapper. Slik kan de kombineres på mange ulike måter, for således sterkt å øke antall proteiner (eller kodede transkripsjoner). 'Gen-mappene' er strukturerte for å muliggjøre masse-genfinning av DNA-filer eller strukturerte for å tillate individuell tilgang på filer.
Videre er 'gen-mapper' eller clustre gruppert, ikke-tilfeldig, langs kromosomer for å danne høyere ordens mapper. Noen DNA-elementer modulerer aktiviteter til genomet. Andre agererer som kromosom-'stillas' for å flette sammen DNA i cellekjernen . 'Gen-mapper 'grupperes for å danne supermapper. Disse grupperingene (clustre) utfører mange slags aktiviteter, som en først nå oppdager virkemåten til.
Kombinasjon av gen-supermapper, grupperes inn i enda større sammenhenger av 'like-gjøremål' (isochores). Disse isochores har som oppgave å regulere relasjoner mellom nærliggende kromosomer i cellekjernen. De tjener også som et rammeverk for dannelse av organell-liknende samlinger. Dette er trolig bare de lavere lagene av ennå uoppdagede høyere lags koder. Datafolk får en slags déja-vu når vi møter hierarkiske fil-strukturer i biologiske organismer.
Om informasjonen i DNA og kromosomer skulle vært dannet av ikke-styrte prosesser ved prøving og feiling, ville en knapt vente å finne ikke-tilfeldig funksjons-spesifikk informasjon med genetiske filer, inni mapper, som er inni supermapper og isochores. En ville heller ikke vente at celler ville produsere gen-produkter med presis målstyrt og spesifikk effektivitet, om det var dannet ved tilfeldige mutasjoner. Den hierarkiske strukturen med mange slags informasjon knyttet til det samme biologiske mediet, synes å ha kreve betraktelig planlegging og forberedelse. Alt dette er med å styrke forklaringsevnen og gjøre ID til den beste, mest årsaks-tilstrekkelige forklaring for opphavet til og dannelsen av cellens informasjonssystem.
 3. Informasjons kontekst inni og utenfor genomet
3. Informasjons kontekst inni og utenfor genomet
I de siste årene har utviklings og evolusjons-biologer oppdaget at kodende sekvenser i genomet ikke alene bestemmer funksjonen til genproduktet under embryo-utviklingen. Ofte er det den større konteksten(sammenhengen) genene finnes i, som bestemmer den spesifikke funksjonen til proteinene de utvikler. ved å sammenligne gener mellom grupper, har biologer oppdaget at hovedsakelig identiske sekvenser regulerer meget forskjellige strukturer i ulike organismer.
Genet 'distal-less' og dets like fungerer som brytere (switches), men i hvert tilfelle en 'bryter' som regulerer mange ulike gener, som leder til ulike anatomiske trekk, igjen avhengig av den større informasjons-konteksten genet befinner seg. Selv om det dreide seg om en generell, bred klasse (appendages), hadde de lite til felles med hverandre. Genet fantes i fjernt relaterte organismer, etter evolusjonistisk syn. I det hele syntes det vanskelig å forklare ut fra ortodoks-evolusjonisme hvordan like gener kunne ha så ulike funksjoner i ulike settinger. Der har en antatt at gener kontrollerer utviklingen og at like gener skulle danne like organismer og strukturer. Denne oppdagelsen problematiserer også påstander om likt opphav, når samme gentype finnes i 'fjernt beslektede' arter.
Ut fra erfaring med informasjonssystemer dannet av intelligente aktører, er det ikke uventet at en har slik kontekst-avhengig virkemåte. Gettysburg-talen består f.eks. av 49 ulike ord. Av de samme 49 ordene er det også dannet et anarkist-manifest, med bortimot diametralt motsatt mening. Det er ikke ordene, men arrangeringen av ordene som er ulike i de to tilfellene. Kontekst-avhengigheten til de mindre modulene de er bygd opp av, viser at funksjonen er bestemt av et større informasjonssystem, og fortrinnsvis først når dette er på plass. Funksjonen til mange gener og proteiner blir bestemt 'top-down', ikke 'bottom-up' som evolusjonister antar. Mutasjoner virker fortrinnsvis på gener, som så igjen påvirker kromosomer og celler..
Dette trigger spørsmålet: Hvordan kunne gener og proteiner ha overlevd og formert seg, før den eksterne og komplekse organisme-konteksten, som bestemmer virkemåten, fantes? Dette trekket ved gener synes forbløffende (puzzling) for evolusjonsteorien. Det blir ikke bare et super-komplisert puslespill, men å holde det i live uten 'styring ovenfra' synes uholdbart. Ut fra ID som har rom for et forsyn, en planleggende intelligens, virker imidlertid dette ikke ødeleggende.
Høyere ordens, strukturell informasjon synes spille en avgjørende rolle for utvikling av organismer. Biologer vet ikke hvor alle denne informasjonen utenom genomet befinner seg, men har lokalisert noe. For eks. vet de at strukturen og lokaliseringen til celle-skjelettet spiller inn på utviklingen av embryoet. I tillegg påvirker lokalisering av spesifikke mål-steder på innsiden av celle-membranen formen på celle-skjelletet og influerer utviklingen av organisme-formen. Selv om disse er laget av proteiner, er det ikke bare proteinet, men plasseringen og den tre-dimensjonale strukturelle informasjonen som bestemmer strukturen på celleskjelettet og lokaliseringen av dets mindre enheter. I encellede organismer kan kutt i celle-membranen danne arvelige endringer i membran-mønstre, selv om DNA ikke er skadet.
I det hele bestemmes formen og strukturen til cella av både gener og tidligere tredimensjonale-strukturer og deres organisering. Proteiner transporteres og finner fram, til riktig adresse delvis p.g.a. tidligere tredimensjonale-strukturer og deres organisering. (Nobel-prisen i medisin 2013 gikk til celle-biologer for deres arbeid med cellens transport-system..) Gener forsyner nødvendig, men ikke tilstrekkelig informasjon for utvikling av de tre dimensjonale former og strukturer de produserer i celler og for kroppsbygning. Således kan gener mutere i det uendelige uten at de påvirker større formmessige endringer.
En analogi kan sees til fysikk, der organiseringen av transistorer, motstand og kondensatorer er det som bestemmer virkemåten av elektronikken, ikke delene i seg selv. Organismer inneholder både informasjonsrike proteiner og gener, og danner informasjonsrike arrangement av disse komponentene i form av hierarkisk oppbygde systemer. Et rikt flerlags-informasjon hierarki er ikke uventet fra ID-hold. At biologiske organismer har slik oppbygning understreker ytterligere relevansen til ID.
Aktuelle forskningsspørsmål.
Det hevdes ofte at ID ikke fremmer noen aktuelle forskningsspørsmål. Dette er en del av debatten, da aktualiteten av forsknings-spørsmålene avhenger av dem som ser.
Cellens informasjons- og lagringssystem manifesterer helt klart mange trekk: hierarkisk 'filstruktur', flettede koding av informasjon, kontekst-avhengighet for lavere grads informasjons-moduler og sofistikerte strategier for å øke lagringskapasitet, som vi ville vente å finne om systemene var intelligent designet.
Dis se informasjons-kjennetegnene er funnet både i encellede bakterier (prokaryotes) og høyere ordens flercellede organismer. Dette gir opphav til flere radikale, muligheter (-som for tiden møter motstand fra neo-darwinismen): Neo darwinismen regner med at genetisk informasjon er kontekst-uavhengig, at gener har uavhengig tilknytning og at de kan mutere på ubestemt tid, med lite aktelse til forhold utenfor genomet og andre funksjonelle beskrankninger.
se informasjons-kjennetegnene er funnet både i encellede bakterier (prokaryotes) og høyere ordens flercellede organismer. Dette gir opphav til flere radikale, muligheter (-som for tiden møter motstand fra neo-darwinismen): Neo darwinismen regner med at genetisk informasjon er kontekst-uavhengig, at gener har uavhengig tilknytning og at de kan mutere på ubestemt tid, med lite aktelse til forhold utenfor genomet og andre funksjonelle beskrankninger.
Design-teoretisk perspektiv synes å oppmuntre til forskning på hierarkiske informasjons-strukturer i cellen, som neo-darwinismen synes neglisjere. Dette er spørsmål som: hvor finnes slik utenom-genom aktig informasjon, hvor mange typer informasjon er det i cellen, kan slik informasjon måles -gitt at den er strukturell og dynamisk? Og hvor muterbar er ulike former for ikke-DNA basert informasjon -om i det hele tatt?
Vi vet også at dyrs kroppsbygning er statiske over lange perioder. Er denne morfologiske tilstanden resultat av begrensninger på muterbarhet grunnet interavhengighet av informasjonshierarkier? Gitt fenomenet fenotype- (fremtoningspreg/egenskapstype) plastisitet at organismer med samme genotype (genetisk konstitusjon/arveanlegg) har ulike fenotyper. Ut fra det kan en spørre hvor mye av variasjonen i organismer er resultat av 'preprogrammering' i motsetning til tilfeldige mutasjoner? Om gjentatte variasjoner stammer fra preprogrammering, hvor befinner den nødvendige informasjonen seg og hvordan kommer den til uttrykk?
Noen spørsmål går på effektiviteten til evolusjonære mekanismer. Kan disse mekanismene forklare ulike design og kanskje også en designende intelligens? Hvor store endringer kan ikke-styrte prosesser som mutasjoner og utvalg danne? Kan de produsere nye proteiner, for ikke å si nye anatomiske? Eller er det kanskje andre design-mønstre kjent fra programvare-design eller mekanisk bygging som kan forklare trekk vi finner? Motsatt om ikke-styrte evolusjonære mekanismer er tilstrekkelige for å gjøre rede for opphavet til alle nye livsformer: er det mulig at gjennomtrengende tegn på design i høyere livsformer var preprogrammert for å folde seg ut fra livets opprinnelse av?
Design argumenter som irreduserbar kompleksitet stiller også spørsmål som må avklares: Er spesifikke molekylære maskiner irreduserbart komplekse? Det innebærer at de ikke kan bygges gradvis opp, eller med andre ord: om en del/funksjon ikke virker, vil ingenting virke. Noen slike spørsmål virker radikale ut fra neo-darwinistisk syn og flere av deres forskere vil ikke ha noen befatning med spørsmålene. Men uansett kan de ikke hevde at forskere som vil befatte seg med spørsmålene ikke vil ha noe å gjøre eller at saken med ID er blitt svekket etter nye funn om genomet!
(Animasjon: molecular machines in cell)
Kilder:
Amaral og Mattick, "Noncoding RNA in Development"
Carvalho et al., "Chromsomal G-dark Bands Determine the Spatial Organization of Centromeric Heterochromatin in the Nucleus."
Constantini et al., "Human Chromosomal Bands."
Denoeud et al. "Prominent Use of Distal5^ Transcription Start Sites."
Gierman, et al, "Domain Wide Regulation of Gene Expression in the Human Genome"; Goetze et al., "The Three-Dimensional Structure of Human Interphase Chromosomes."
Harold, "From Morphogenes to Morphogenesis."
Karpranov, Willingham og Gingeras, "Genome-wide Transcription and the Implicatisons for Genomic Organization"
Moss, "What Genes Can't do."
Savarese og Grosschedl, "Blurring Cis ond Trans in Gene Regulation"
Panganiban og Rubenstin, "Development Functions of the Distal-less/Dix Homeobox Genes."
Squires and Berry, "Eukaryotic Selenoprotein Synthesis"
Oversatt -og til .htm-format ved Asbjørn E. Lund.